摘要
本文部分内容来源于网络,个人收集整理,请勿传播
本文学习过程中记录
经过几天路飞学院爬虫课程的学习,了解了爬虫的本质以及相关的基本知识,今天开始学习爬虫框架scrapy。
前两天的课程学习中应用的是requests和bs4模块,scrapy框架与这两个模块相比无论是速度还是在便捷性上提高的不是一点半点,但是前两天的学习并不是无用的。
前两天的学习了解到整个爬虫的思想以及流程,还有理解如何提高爬虫效率的方法,能够在学习scrapy框架的过程中更深入理解,有一种恍然大悟的感觉,整个学习过程是循序渐进的,感谢路飞学院的这次课程。
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
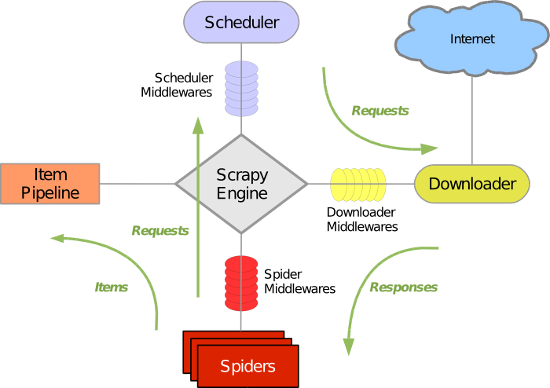
由于ansible与agent之间的通信使用的是openssh,每次新增机器之后需要在ansible的inventory文件中添加新增机器的相关配置。虽然配置起来很简单,但是一旦短时间新增大量机器、或者是长时间的维护过程中难免会有遗漏或配置重复的情况出现,因此类似salt的agent自动向server注册的功能就显得十分重要。
目前为至还未发现世面上有这种类似saltstack的agent自动向server端自动注册的机制,其实实现起来很简单,也不需要修改现有的ansible,只需要用到几个服务,以及手写几个脚本就可以按照你自己定义好的规则实现自动注册。
本文部分内容来源于网络,个人收集整理,请勿传播
ansible是目前非常火的运维自动化批量管理工具之一
ansible和saltstack都是使用python语言写的,而在选择以及使用的过程中,ansible相对saltstack具有以下几个优势
本文部分内容来源于网络,个人收集整理,请勿传播
shell中截取字符串有很多种方法,通常情况可以使用sed、awk、cut来进行字符串切割,本文使用的是shell中字符串本身具有的字符串切割方法
1 | ${expression} |