摘要
本文内容转自网络,个人学习记录使用,请勿传播
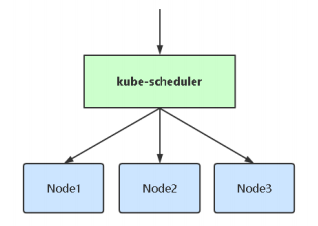
创建一个Pod的工作流程
k8s集群基于list-watch(消息队列监听?)机制的控制器架构,实现组件间交互的解耦。k8s集群中的组件一直监听自己负责的资源,当这些资源发生变化时,kube-apiserver会通知这些组件,这个过程类似于消息队列的发布和订阅。

kubectl run nginx-demo --image=nginx:1.17.10:用户通过kubectl命令发起创建pod指令,kubectl将用户输入的指令发送给apiserver,apiserver将数据存储到etcd中。- scheduler根据自己的调度算法为创建的pod选择一个合适的节点,并给pod打一个label:
nodeName=k8s-node01,并将结果返回给apiserver,apiserver将数据存储到etcd中。 - kubelet发现有新的pod分配到自己所在的节点,调用docker-api创建容器,并将容器状态返回给apiserver,apiserver将数据存储在etcd中
- 用户通过kubectl命令可以查询到pod的状态和信息。
controller-manager:负责常规的后台任务,如deployment
kube-proxy:负责容器的网络,如service的实现
Pod中影响调度的主要属性
1 | apiVersion: apps/v1 |
资源限制对Pod调度的影响
1 | apiVersion: apps/v1 |
CPU单位:可以写m也可以写浮点数,例如0.5=500m,1=1000m
K8s会根据Request的值去查找有足够资源的Node来调度此Pod
k8s调度器会根据pod的资源限制(requests)以及各个节点的资源使用情况对pod进行调度
- limits:用来限制容器中应用使用的最大资源限制
- requests:容器需要的资源值,在容器分配时会作为资源分配的参考依据,通过此参数判断node是否能容纳当前容器
- requests一般建议小于limits的20%~30%,且requests必须小于limits
- 节点上limits的总和建议不要超过物理机实际配置的20%(实际情况应根据业务属性,流量等诸多因素进行压测、评估)
- 当requests的值没有节点能够满足时,pod会一直处于pendding状态,等待有足够的资源才能够进行分配
容器资源限制
resources.limits.cpuresources.limits.memory
容器使用的最小资源要求(作为容器调度时资源分配的依据)
resources.requests.cpuresources.requests.memory
NodeSelector和NodeAffinity
NodeSelector
可以将Pod调度到匹配Label的Node上,如果没有匹配的标签就会调度失败
作用
- 约束Pod到特定节点上运行
- 完全匹配节点标签
- 如果目标节点没有资源可调度,或者目标标签不存在,则Pod会处于Pending状态
应用场景
- 专用节点:根据业务线将Node进行分组管理(打不同的Label)
- 配备特殊硬件:根据硬件熟悉为Nodo打不同的标签,调度时进行特殊调度,如:SSD,GPU
示例
1 | # 将节点打标签 |
1 | apiVersion: apps/v1 |
1 | $ kubectl apply -f nginx-disk.yaml |
NodeAffinity
用于节点亲和策略,和NodeSelector类似,可以根据节点上的Label来约束Pod可以调度到哪些节点上
- 相比NodeSelector有更多的逻辑判断条件
- 支持的操作:
In,NotIn,Exists,DoesNotExist,Gt,Lt - 调度策略分为软策略和硬策略,不是完全的影响要求
- 软策略(
preferred):尝试满足策略 - 硬策略(
required):必须满足策略
- 软策略(
示例
1 | apiVersion: apps/v1 |
1 | $ kubectl get pod -l app=nginx-affinity |
Taints和Tolerations
Taints:给node设置污点,避免Pod被调度到这个节点上Tolerations:给Pod设置容忍污点,允许Pod被调度到有污点的节点上
应用场景
- 专用节点:根据业务情况将部分Node分组,需要Pod默认不要调度到这组节点上,只有配置了污点容忍的应用才会分配到这组node上
- 配备特殊硬件:部分Node配有特殊硬件,如:SSD,GPU,希望默认情况下不调度节点
- 基于污点的Pod驱逐
调度策略[effect]
1 | # 添加污点 |
NoSchedule: 一定不能被调度PreferNoSchedule:尽量不要调度,可以不配置容忍NoExecute:不仅不会调度,还会驱逐Node上已有的Pod
示例
1 | # 给节点添加污点 |
如果希望Pod可以分配到带有污点的节点上,需要添加容忍字段tolerations
1 | apiVersion: apps/v1 |
1 | # 会匹配key的所有污点 |
污点结论
公共部分
- pod调度策略允许污点并且表达式满足污点匹配的情况下,pod可以调度到污点节点上
- 已调度允许的pod更新后不满足污点策略时,污点上的pod会销毁重新调度
- 同理,污点不匹配的pod更新后满足污点容忍也有可能重新调度到污点节点上
- 去除节点的污点不会触发pod重新调度
当污点调度策略为NoSchedule时
- 已分配Pod的节点新增不匹配的污点,节点上的Pod不会被驱逐,更新了Pod的配置后如果不满足Pod才会重新调度
当污点调度策略为NoExecute时
- 添加污点时会驱逐节点上所有没有污点容忍或污点容忍不匹配的Pod
有多个污点的情况
- 多个污点只有一个满足容忍的情况下,Pod无法调度
- 已调度到污点上的Pod
- 节点新增
NoSchedule策略不匹配污点,Pod不会重新调度 - 节点新增
NoExecute策略不匹配污点,Pod会重新调度
- 节点新增
- 多个污点都容忍的情况下Pod才能调度到污点节点
NodeName
指定节点名称,用于将Pod调度到指定的Node上,不经过调度器
- 因此这种方式无视污点和节点标签,直接进行部署
1 | apiVersion: v1 |
1 | $ kubectl apply -f nginx-nodename.yaml |
DaemonSet控制器
- 会在每一个Node上运行一个Pod,且只会运行一个
- 新加入到集群中的新Node也会自动创建运行一个Pod

应用场景
- 网络组件
- 监控Agent
- 日志Agent
示例
1 | apiVersion: apps/v1 |
1 | $ kubectl apply -f filebeat.yaml |
1 | apiVersion: apps/v1 |
调度失败的原因分析
1 | # 查看Pod的调度结果 |
调度失败可能的原因
- 节点资源不足(CPU、内存等)
- 节点有污点,切调度策略没有容忍污点
- 没有匹配到节点标签