摘要
本文内容转自网络,个人学习记录使用,请勿传播
kubelet、docker、containerd和runc之间的架构关系
总署
参考资料:
https://zhuanlan.zhihu.com/p/58784095 (推荐)
https://www.zhihu.com/question/324124344/answer/681389308(推荐)

当 Kubelet 想要创建一个容器时, 有这么几步:
- Kubelet 通过 CRI 接口(gRPC) 调用 dockershim, 请求创建一个容器. CRI 即容器运行时接口(Container Runtime Interface), 这一步中, Kubelet 可以视作一个简单的 CRI Client, 而 dockershim 就是接收请求的 Server. 目前 dockershim 的代码其实是内嵌在 Kubelet 中的, 所以接收调用的凑巧就是 Kubelet 进程;
- dockershim 收到请求后, 转化成 Docker Daemon 能听懂的请求, 发到 Docker Daemon 上请求创建一个容器;
- Docker Daemon 早在 1.12 版本中就已经将针对容器的操作移到另一个守护进程—containerd守护进程, 因此 Docker Daemon 仍然不能帮我们创建容器, 而是要请求 containerd 创建一个容器;
- containerd 收到请求后, 并不会自己直接去操作容器, 而是创建一个叫做 containerd-shim 的进程, 让 containerd-shim 去操作容器. 这是因为容器进程需要一个父进程来做诸如收集状态, 维持 stdin 等 fd 打开等工作. 而假如这个父进程就是 containerd, 那每次 containerd 挂掉或升级, 整个宿主机上所有的容器都得退出了. 而引入了 containerd-shim 就规避了这个问题(containerd 和 shim 并不是父子进程关系);
- 我们知道创建容器需要做一些设置 namespaces 和 cgroups, 挂载 root filesystem 等等操作, 而这些事该怎么做已经有了公开的规范了, 那就是 OCI(Open Container Initiative, 开放容器标准). 它的一个参考实现叫做 runc. 于是, containerd-shim 在这一步需要调用
runc这个命令行工具, 来启动容器; runc启动完容器后本身会直接退出, containerd-shim 则会成为容器进程的父进程, 负责收集容器进程的状态, 上报给 containerd, 并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理, 确保不会出现僵尸进程
问题
问题1 CRI是什么?
CRI全名container runtime interface,是kubernetes官方在1.5版本推出的一份容器运行时接口,目的是为了统一容器运行时接口。如果其他容器厂商,想要他们的容器产品能够使用kubernetes,就需要实现这些接口,方便kubernetes的调用。
问题2 OCI是什么?
OCI规范(Open Container Initiative 开放容器标准),该规范包含两部分内容:容器运行时标准(runtime spec)、容器镜像标准(image spec)。
其就是一份文档,文档可见
问题3 可否跳过docker-daemon,直接调用containerd?
答案是可以的
支持OCI和CRI的都能够通过以下形式调用,图片来自https://www.zhihu.com/question/324124344/answer/681389308

对这张图的简化之后,可以分解出以下的调用关系:

问题4 有这么多runtime的东西,有没有一个层次关系呢?

参考资料:
- https://www.ianlewis.org/en/container-runtimes-part-1-introduction-container-r
- https://www.ianlewis.org/en/container-runtimes-part-2-anatomy-low-level-contai
- https://www.ianlewis.org/en/container-runtimes-part-3-high-level-runtimes
- https://www.ianlewis.org/en/container-runtimes-part-4-kubernetes-container-run
全部参考文献
https://my.oschina.net/u/2306127/blog/1600270
https://www.jianshu.com/p/d9bf66841a1e
https://www.infoq.cn/article/2017/02/Docker-Containerd-RunC/
介绍containerd-shim作用的链接https://groups.google.com/g/docker-dev/c/zaZFlvIx1_k
docker的历史:https://zhuanlan.zhihu.com/p/105331409
containerd源代码学习计划
component说明
The following table specifies the various components of containerd and general features of container runtimes. The table specifies whether or not the feature/component is in or out of scope.
| Name | Description | In/Out | Reason |
|---|---|---|---|
| execution | Provide an extensible execution layer for executing a container | in | Create,start, stop pause, resume exec, signal, delete |
| cow filesystem | Built in functionality for overlay, aufs, and other copy on write filesystems for containers | in | |
| distribution | Having the ability to push and pull images as well as operations on images as a first class API object | in | containerd will fully support the management and retrieval of images |
| metrics | container-level metrics, cgroup stats, and OOM events | in |
.png)
学习目标
对源代码containerd和containerd-shim有个初步的了解
- 对项目的运行有一个基本的了解
- 对各个模块的运行和作用有基本的了解
- 对各模块之间的调用关系有基础的了解
- 对相关的技术有基本的了解
学习之后的效果:
- 团队对容器的了解程度有一个质变的过程
- 对containerd的相关的运行逻辑有所了解
学习分享
两周or三周or四周一次
分享内容包括(可选):
- 代码架构级别
- 探索代码的实现流程
学习总结
学习完之后对使用到的linux特性有一个了解,对runc的运行流程有比较清晰的认识,总结文档分享人在此文档的子页面中新创建一个文档,进行总结。总结内容不限
学习计划
根据ctr提供的13种服务中的主要服务来学习,从ctr指令入手,发掘对应的后台实现和逻辑,从ctr/commands目录开始
plugins,container,content,events, event,images,leases,
namespaces,pprof,run,snapshots, tasks, shim,cri。
| 时间 | 分享人 | 学习内容 | 进度 | 优先级 | 学习内容摘要 |
|---|---|---|---|---|---|
| 项目相关的文档阅读了解项目架构和运行流程了解项目命令行工具的使用(containerd,containerd-shim,containerd-stress,ctr) | 1 | 学习源代码中的文档大致了解部分运行过程熟悉ctr工具的使用 | |||
| content,snapshot | 1 | content负责保存 blob 的模块,包括1.镜像的 manifest(一个普通的 json,其中指定了镜像的 config 和镜像的 layers 数组);2.镜像的 config(同样是个 json,其中指定镜像的元信息,比如启动命令、环境变量等);3.镜像的 layer(tar 包,解压、处理后会生成镜像的层) snapshots 用于镜像的 rootfs 挂载和卸载等 | |||
| images,containers,run | 1 | images底层镜像管理;containers比docker底层的容器管理,run运行容器 | |||
| task,event | 1 | 任务管理和容器事件管理 | |||
| namespaces | 1 | 命名空间的管理; | |||
| leases,shim | leases对leases的管理;shim由于shim进程的交互,实现对task进程的交互,与容器创建相关 |
runc源代码学习计划
学习的内容
- namespace
- cgroup v1
- runc源代码
学习目的
- 了解linux的namespace和cgroup v1,Linux Capabilities的运行原理
- 了解runc的运行流程
- 了解runc子模块的的作用
学习分享
两周or三周or四周一次
分享内容包括(可选):
- 使用到的技术分享
- 代码架构级别
学习总结
学习完之后对使用到的linux特性有一个了解,对runc的运行流程有比较清晰的认识,总结文档分享人在此文档的子页面中新创建一个文档,进行总结。总结内容不限
学习计划
| 时间 | 分享人 | 学习内容 | 进度 | 优先级 | 学习内容目录摘要 | |
|---|---|---|---|---|---|---|
| 1 | cgroup知识namespace知识runc命令行实战项目总揽(3000行代码,markdown、shell、makefile等) | 20% | 1 | cgroup的基本知识namespace的基本知识runc的基本知识项目的开发流程和模块分解 | ||
| 2 | runc命令行代码(runc目录下的go后缀文件)(3403行) | 10% | 2 | 了解命令行是如何与后台运行的 | ||
| 3 | libcontainer目录下的go后缀文件(不包含子目录)(6541行)factory.go factory_linux.go 类似于工厂类container.go container_linux.go容器对象process进程对象…. | 40% | 1 | 这些文件主要包括了为用户提供容器创建,运行,停止,查看的对外接口 | ||
| 4 | libcontainer的子目录(12000行)cgroup对cgroup的封装config对基本配置的封装apparmor限制安全nsenter,c语言代码seccompspecconv,配置转换user用户相关systemutilslogskeysdevices | 30% | 2 | 底层 |
分享目的
- 了解cgroup的组织结构和linux是如何对cgroup进行基本的组织来实现对一个进程或多个进程进行资源的限制
- 了解namespace的基本概念和通过一个简单的例子实现如何对进程进行namespace的限制
- 了解containerd和runc的运行流程
- 了解containerd和runc中的基本概念
分享的内容
- cgroup的组织结构
- containerd中task的生命周期
- runc的运行流程
- ….
cgroups
名词翻译
层级树 hierarchies
进程 process
子系统 subsystem 也可以把一类cgroup controller叫做一个subsystem
注意:
Remember that system processes are called tasks in cgroup terminology.
在cgroup的术语中,系统进程(system process)是被叫做任务task。
Cgroup
全程:control groups, 通过使用cgroup让用户对资源进行分配,分配的资源包括:
- cpu time
- system memory
- network bandwidth
- 集合多个资源一起分配
control groups提供了一种对进程进行层次化分组和标记同时也能够对其进行资源限制的方式,使用 cgroup,系统管理员可更具体地控制对系统资源的分配、优先顺序、拒绝、管理和监控。可更好地根据任务和用户分配硬件资源,提高总体效率。
Control Groups provide a way to hierarchically group and label processes, and to apply resource limits to them
为什么不用niceness来实现资源的隔离呢?
因为niceness在进程层次进行资源限制,这样导致了越多进程的应用(application)也将会使用更多的资源,这将导致进程数少的但是重要的应用被限制,使用cgroup将系统对进程层次的资源限制提升到了对应用层次的资源限制,在centos7中使用systemd启动的应用将使用cgroup的层级树对对应用资源进行限制
想查看当前的挂载的资源控制器(resource controller)可以在/proc/cgroups\找到,或者使用命令行lssubsys
Cgroug是怎么组织的?
The Linux process model
- linux进程中,除了Init进程是在内核boot的时候创建的,子进程(child process)都是Init进程创建的子进程——进程模型是层次性的或者说是一棵树
- 除了Init进程外,子进程(child process)将会继承父进程(parent process)的环境,比如(环境变量)——-父子进程间存在继承关系
The parent process is able to alter the environment before passing it to a child process.
The Cgroup model
cgroup模型和进程模型很像:
- cgroup结构是层级树的
- 子cgroup(child cgroup)会继承父cgroup(parent cgroup)的一些属性
两个模型的不同点
The fundamental difference is that many different hierarchies of cgroups can exist simultaneously on a system.
最基本的不同就是,多个不同的cgroup层级树可以同时在系统中存在。
If the Linux process model is a single tree of processes, then the cgroup model is one or more separate, unconnected trees of tasks (i.e. processes).
如果一个linux的进程模型是单一的树结构,那么cgroup模型就是一个或者多个独立的、不相连的任务树。
多个cgroup层级树是很需要的,因为每一个cgroup层级树都将被依附到一个或者多个子系统中
什么是子系统(subsystem)
A subsystem represents a single resource, such as CPU time or memory.
You should be aware that subsystems are also called resource controllers, or simply controllers, in the libcgroup man pages and other documentation.
一种子系统就是一种单一的资源,cpu subsystem 是一种cpu子系统,用于调度cgroup的任务(task)使用cpu。在术语表中查看subsystem
注意: resource controller 或者simply controller in cgroup literature 和subsystem是对等的。
a subsystem typically schedules a resource or applies a limit to the cgroups in the hierarchy it is attached to.
The definition of a subsystem (resource controller) is quite general: it is something that acts upon a group of tasks, i.e. processes.
RELATIONSHIPS BETWEEN SUBSYSTEMS(子系统), HIERARCHIES(层级树), CONTROL GROUPS(控制组群) AND TASKS(任务)
规则1
A single hierarchy can have one or more subsystems attached to it.
一个单一的hierarchy可以有一个或多个subsystem依附于它

可以从图中可以看出,一个cgroup hierarchy被依附上cpu和memory两种subsystem
规则2
Any single subsystem (such as cpu) cannot be attached to more than one hierarchy if one of those hierarchies has a different subsystem attached to it already.
As a consequence, the cpu subsystem can never be attached to two different hierarchies if one of those hierarchies already has the memory subsystem attached to it. However, a single subsystem can be attached to two hierarchies if both of those hierarchies have only that subsystem attached.
比如当两个hierarchy中,其中一个被memory subsystem附上,那么cpu subsystem不能同时被附在这两个不同hierarchy上
当两个hierarchy,没有其他的subsystem附在其中一个上的时候,一个单一的subsystem可以同时被附在这两个不同的hierarchy上
为什么会有这样的规则呢? task可以是到多个hierarchy中的cgoup成员,task被分配到两个hierarchy中,并且两个hierarchy都对cpu进行分配,那么将对task的cpu分配造成冲突,这将产生前后矛盾的问题。

规则3
Each time a new hierarchy is created on the systems, all tasks on the system are initially members of the default cgroup of that hierarchy, which is known as the root cgroup. For any single hierarchy you create, each task on the system can be a member of exactly one cgroup in that hierarchy. A single task may be in multiple cgroups, as long as each of those cgroups is in a different hierarchy. As soon as a task becomes a member of a second cgroup in the same hierarchy, it is removed from the first cgroup in that hierarchy. At no time is a task ever in two different cgroups in the same hierarchy.

cpu和memory subsystem被依附到名为cpu_mem_cg的层级树上,net_cls被依附到名为net的层级树上,那么httpd进程可以是cpu_mem_cg层级树中任意一个cgoup成员,也可以是net层级树中任意一个cgroup成员,
所以进程在对应的层级树中只能对应一个cgoup成员
httpd进程是cpu_mem_cg层级树上的cgroup中的成员cg1上,来实现对httpd进程的cpu和memory的限制;同时httpd进程是net层级树上cgroup的成员cg3上,来实现对net_cls的限制
When the first hierarchy is created, every task on the system is a member of at least one cgroup: the root cgroup. When using cgroups, therefore, every system task is always in at least one cgroup.
当第一个hierarchy被创建的时候,在系统中的每个task都至少是一个cgroup的成员,起码也是root cgroup的成员,所以,当用cgroup的时候,每个任务都至少是一个cgroup的成员。
规则4
Any process (task) on the system which forks itself creates a child task. A child task automatically inherits the cgroup membership of its parent but can be moved to different cgroups as needed. Once forked, the parent and child processes are completely independent.

cpu_and_mem 层级中名为 half_cpu_1gb_max 的 cgroup 成员的任务,以及 net 层级中 cgroup trans_rate_30 的成员。当 httpd 进程将其自身分成几个分支时,其子进程会自动成为 half_cpu_1gb_max cgroup 和 trans_rate_30 cgroup 的成员。它会完全继承其父任务所属的同一 cgroup。
此后,父任务和子任务就彼此完全独立:更改某个任务所属 cgroup 不会影响到另一个。同样更改父任务的 cgroup 也不会以任何方式影响其子任务。总之:所有子任务总是可继承其父任务的同一 cgroup 的成员关系,但之后可更改或者删除那些成员关系。
注意事项
- Because a task can belong to only a single cgroup in any one hierarchy, there is only one way that a task can be limited or affected by any single subsystem. This is logical: a feature, not a limitation.
- You can group several subsystems together so that they affect all tasks in a single hierarchy. Because cgroups in that hierarchy have different parameters set, those tasks will be affected differently.
- It may sometimes be necessary to refactor a hierarchy. An example would be removing a subsystem from a hierarchy that has several subsystems attached, and attaching it to a new, separate hierarchy.
- 不需要那么多的hierarchy的时候,Conversely, if the need for splitting subsystems among separate hierarchies is reduced, you can remove a hierarchy and attach its subsystems to an existing one.
- 简单化使用The design allows for simple cgroup usage, such as setting a few parameters for specific tasks in a single hierarchy, such as one with just the
cpuandmemorysubsystems attached. - 精细化配置The design also allows for highly specific configuration: each task (process) on a system could be a member of each hierarchy, each of which has a single attached subsystem. Such a configuration would give the system administrator absolute control over all parameters for every single task.
使用cgroup v1
使用libcgroup来使用cgroup(针对系统centos6)
1 | # 下载 |
使用systemd来使用cgroup(针对centos7)
创建cgroup
从systemd的角度来看,一个cgroup绑定到一个系统单元(system unit configurable),该系统单元可以用一个单元文件进行配置,并且可以通过systemd的命令行实用程序进行管理。根据应用程序的类型,您的资源管理设置可以是临时的或永久的。
要为服务创建一个临时cgroup,请使用以下systemd-run命令启动该服务。这样,可以对服务在其运行期间消耗的资源设置限制。停止服务后,便会自动删除临时单元。
要将持久性cgroup分配给服务,编辑其单元配置文件。重新启动系统后,该配置将保留下来,因此可用于管理自动启动的服务。使用systemctl enable,可在https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/system_administrators_guide/index查看
术语表
- task(任务):cgroups 的术语中,task 就表示系统的一个进程。
- cgroup(控制组):cgroups 中的资源控制都以 cgroup 为单位实现。cgroup 表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个任务可以加入某个 cgroup,也可以从某个 cgroup 迁移到另外一个 cgroup。
- subsystem(子系统):cgroups 中的 subsystem 就是一个资源调度控制器(Resource Controller)。比如 CPU 子系统可以控制 CPU 时间分配,内存子系统可以限制 cgroup 内存使用量。centos7中的subsystems是
blkio— sets limits on input/output access to and from block devices;cpu— uses the CPU scheduler to provide cgroup tasks access to the CPU. It is mounted together with thecpuacctcontroller on the same mount;cpuacct— creates automatic reports on CPU resources used by tasks in a cgroup. It is mounted together with thecpucontroller on the same mount;cpuset— assigns individual CPUs (on a multicore system) and memory nodes to tasks in a cgroup;devices— allows or denies access to devices for tasks in a cgroup;freezer— suspends or resumes tasks in a cgroup;memory— sets limits on memory use by tasks in a cgroup and generates automatic reports on memory resources used by those tasks;net_cls— tags network packets with a class identifier (classid) that allows the Linux traffic controller (thetccommand) to identify packets originating from a particular cgroup task. A subsystem ofnet_cls, thenet_filter(iptables) can also use this tag to perform actions on such packets. Thenet_filtertags network sockets with a firewall identifier (fwid) that allows the Linux firewall (theiptablescommand) to identify packets (skb->sk) originating from a particular cgroup task;perf_event— enables monitoring cgroups with the perf tool;hugetlb— allows to use virtual memory pages of large sizes and to enforce resource limits on these pages.
- hierarchy(层级树):hierarchy 由一系列 cgroup 以一个树状结构排列而成,每个 hierarchy 通过绑定对应的 subsystem 进行资源调度。hierarchy 中的 cgroup 节点可以包含零或多个子节点,子节点继承父节点的属性。整个系统可以有多个 hierarchy。
https://www.infoq.cn/article/docker-kernel-knowledge-cgroups-resource-isolation
linux namespace
linux namespace技术是针对资源隔离的相关技术,熟悉chroot命令的,可以知道通过使用chroot,让进程将某一个任意的目录为root目录,并且此目录是独立于系统目录的。从这样的方式实现对资源的隔离
以下为linux下的7中namespace:
- Mount - isolate filesystem mount points
- UTS - isolate hostname and domainname
- IPC - isolate interprocess communication (IPC) resources
- PID - isolate the PID number space
- Network - isolate network interfaces
- User - isolate UID/GID number spaces
- Cgroup - isolate cgroup root directory
namespace实战例子
比如类似leetcode这样的代码提交网站,如果没有使用namespace的隔离技术,恶意的开发者,提交了会对服务器有副作用的代码,在代码编译运行的时候势必将会带来严重的问题。
再比如使用ci的时候,如果源代码中存在恶意的代码,在ci中将进行测试等相关工作,可能将影响ci环境的整体稳定性。
linux系统提供了三种创建具有namespace进程的方式:英文解释来自man
- clone(2) - 创建一个进程的时候,创建的时候指定CLONE_NEW**对每个namespace进行指定
- setns(2) - 将一个namespace分配给一个进程,reassociate thread with a namespace
- unshare(2) - run program with some namespaces unshared from parent,创建的子进程,并且子进程可以选择性的不共享父进程的部分namespace
- nsenter - run program with namespaces of other processes,对setns的封装
使用Golang调用namespace的实战
修改其中UTS namespace
在CentOS 7 3.10.0-1062下,go version 1.15
1 | package main |
此代码的功能为,为我们创建一个sh进程,此进程被赋予一个新的UTS namespace,我们可以通过命令行在golang创建的sh进程和此golang进程运行环境的shell进程中对进程的namespace进行查询。
第一步:确保所有运行都在root权限下
sudo su root
第二步:在root的shell中运行
ls -al /proc/self/ns/
结果为:
lrwxrwxrwx 1 root root 0 9月 21 12:22 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 root root 0 9月 21 12:22 mnt -> mnt:[4026531840]
lrwxrwxrwx 1 root root 0 9月 21 12:22 net -> net:[4026531956]
lrwxrwxrwx 1 root root 0 9月 21 12:22 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 9月 21 12:22 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 9月 21 12:22 uts -> uts:[4026531838]
第三步:运行go程序
go run a.go
将产生一个新的sh进程,在此进程中运行
ls -al /proc/self/ns/
结果为:
lrwxrwxrwx 1 root root 0 Sep 21 12:20 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 root root 0 Sep 21 12:20 mnt -> mnt:[4026531840]
lrwxrwxrwx 1 root root 0 Sep 21 12:20 net -> net:[4026531956]
lrwxrwxrwx 1 root root 0 Sep 21 12:20 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 Sep 21 12:20 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Sep 21 12:20 uts -> uts:[4026532351]
分析结果: 可以看出结果中ipc、mnt、net、pid、user都是相同的,估计是namespace没有指定创建的时候会继承父进程相关的namespace,uts两个的namespace不同了,这就实现了uts的隔离。
修改多个namespace
流程和修改一个namespace的一样,就是golang代码变化了,代码如下
1 | package main |
root中的shell,ls -al /proc/self/ns/结果
lrwxrwxrwx 1 root root 0 9月 21 14:16 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 root root 0 9月 21 14:16 mnt -> mnt:[4026531840]
lrwxrwxrwx 1 root root 0 9月 21 14:16 net -> net:[4026531956]
lrwxrwxrwx 1 root root 0 9月 21 14:16 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 9月 21 14:16 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 9月 21 14:16 uts -> uts:[4026531838]
运行golang代码中的sh,ls -al /proc/self/ns/的结果
lrwxrwxrwx 1 65534 65534 0 Sep 21 14:18 ipc -> ipc:[4026532354]
lrwxrwxrwx 1 65534 65534 0 Sep 21 14:18 mnt -> mnt:[4026532352]
lrwxrwxrwx 1 65534 65534 0 Sep 21 14:18 net -> net:[4026532357]
lrwxrwxrwx 1 65534 65534 0 Sep 21 14:18 pid -> pid:[4026532355]
lrwxrwxrwx 1 65534 65534 0 Sep 21 14:18 user -> user:[4026532351]
lrwxrwxrwx 1 65534 65534 0 Sep 21 14:18 uts -> uts:[4026532353]
结果比较:各namespace的inode number都发生了变化,但是上述修改的只是对namespac的创建,但是没有做更多的规则约束,比如uts的namespace中,没有对hostname和Domain进行设置。
上述golang代码中,只是创建
- 创建了一个新的Mount namespace (
CLONE_NEWNS),但是此时的sh进程在主机的mount和rootfs下 - 创建了一个新的PID namespace (
CLONE_NEWPID),但是没有mount一个新的/proc的文件系统 - 创建了一个新的Network namespace (
CLONE_NEWNET) ,但是没有在此namespace中没有接口(应该是和网络有关的接口) - 创建了一个新的User namespace (
CLONE_NEWUSER),但是没有提供一个UID/GID的映射
对user namespace增加设置
在从一个进程fork一个新的子进程的时候,如果不对子进程的namespace做操作的时候,子进程将会继承父进程的相关namespace
下面将使用golang调用user namespace的,来实现一个子进程和父进程 UID和GID不同的程序。
user namespace的大体过程:
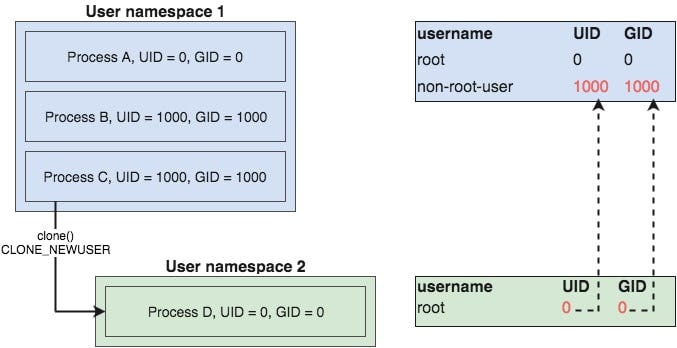
可以看出:当前user namespace有 user namespace 1和user namespace 2,并且两个namespace都维护了两个用户表,user namespace 1中有root和not-root-user两个用户,user space 2中有root一个用户
左侧为在user namespace下运行的进程A、B、C、D。ABC在user namespace 1下运行,D在user namespace 2下运行,其中D是Cfork的一个进程,可以看出通过对两个user namespace中加入一个映射,将namespace 2中0用户能够映射到namespace 1中的1000用户,所以在D进程对于user namespace2中的root用户来运行,对于usernamespace 1来说,是使用not-root-user来运行的。
具体代码实现:
1 | package main |
进入到centos7中的shell中:
第一步:看看当前的进程用户
$ whoami
docker_isme
$ id docker_isme
uid=65926(docker_isme) gid=10000(isme_users) 组=10000(isme_users),1004(docker)
第二步:进入到golang程序创建的sh中
go run a.go
第三步:运行和第一步一样的指令
#whoami
root
#id root
uid=0(root) gid=0(root) groups=0(root)
可以看出在新的进程中用户是root用户,此用户是新的user namespace中的root用户
其他mount namespace,Network namespace,UTS namespace可以在参考资料:
- Part 1: Linux Namespaces
- Part 2: Namespaces in Go - Basics
- Part 3: Namespaces in Go - User
- Part 4: Namespaces in Go - reexec
- Part 5: Namespaces in Go - Mount
- Part 6: Namespaces in Go - Network
- Part 7: Namespaces in Go - UTS
代码可见https://gitlab.isme.pub/docker_isme/ns-process 做了一些整理和修改适应当前golang版本。
这里需要注意的是:在part4中使用到了:reexec,这是docker官方实现的一种在linux系统下,类似linux下的exec命令,不过有些不同,reexec新的特性是在父进程运行结束后\和子进程创建创建前,在这中间可以做一些操作。可见下图

对reexec的学习可以参考https://gitlab.isme.pub/docker_isme/hello-reexec 可以运行,了解运行顺序和逻辑。
科普
exec
fork()是用于建立进程的手段之一,但是fork()只能建立相同程序的副本。幸运的是,Linux系统还提供了系统调用exec系列。它可用于新程序的运行。
如果exec调用成功,调用进程将被覆盖,然后从新程序的入口开始执行。这样就产生了一个新的进程,但是它的进程标识符与调用进程相同。这就是说,exec没有建立一个与调用进程并发的新进程,而是用新进程取代了原来的进程。所以,对exec调用成功后,没有任何数据返回,这与fork()不同。
containerd运行流程

Task的状态图
