摘要
本文内容转自网络,个人学习记录使用,请勿传播
字符串通常有两种设计,一种是「字符」串,一种是「字节」串。「字符」串中的每个字都是定长的,而「字节」串中每个字是不定长的。Go 语言里的字符串是「字节」串,英文字符占用 1 个字节,非英文字符占多个字节。这意味着无法通过位置来快速定位出一个完整的字符来,而必须通过遍历的方式来逐个获取单个字符。
byte与rune的关系
字符通常是指unicode,可以认为所有的英文和汉字在 unicode 字符集中都有一个唯一的整数编号,一个 unicode 通常用 4 个字节来表示,对应到go中的字符rune。
1 | type rune int32 |
使用「字符」串来表示字符串势必会浪费空间,因为所有的英文字符本来只需要 1 个字节来表示,用 rune 字符来表示的话那么剩余的 3 个字节都是零。但是「字符」串有一个好处,那就是可以快速定位。
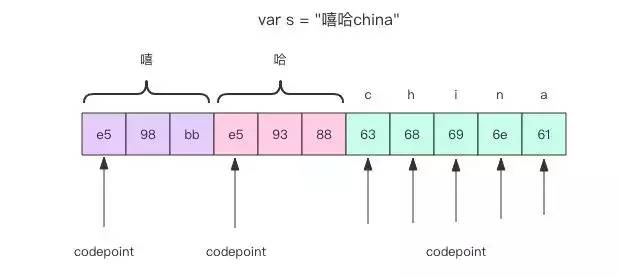
其中 codepoint 是每个「字」的真实偏移量
而 Go 语言的字符串采用 utf8 编码,中文汉字通常需要占用 3 个字节,英文只需要 1 个字节。len() 函数得到的是字节的数量,通过下标来访问字符串得到的是「字节」。
- byte 等同于uint8,常用来处理ascii字符
- rune 等同于int32,常用来处理unicode或utf-8字符
遍历
bytes
1 | package main |
rune
1 | package main |
对字符串进行 range 遍历,每次迭代出两个变量 codepoint 和 runeValue。codepoint 表示字符起始位置,runeValue 表示对应的 unicode 编码(类型是 rune)。
内存表示
如果字符串仅仅是字节数组,那字符串的长度信息是怎么得到呢?要是字符串都是字面量的话,长度尚可以在编译期计算出来,但是如果字符串是运行时构造的,那长度又是如何得到的呢?
1 | var s1 = "hello" // 静态字面量 |
为解释这点,就必须了解字符串的内存结构,它不仅仅是前面提到的那个字节数组,编译器还为它分配了头部字段来存储长度信息和指向底层字节数组的指针,图示如下,结构非常类似于切片,区别是头部少了一个容量字段。
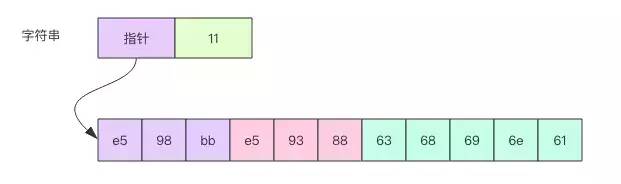
当我们将一个字符串变量赋值给另一个字符串变量时,底层的字节数组是共享的,它只是浅拷贝了头部字段。
字符串是只读的
你可以使用下标来读取字符串指定位置的字节,但是你无法修改这个位置上的字节内容。如果你尝试使用下标赋值,编译器在语法上直接拒绝你。
1 | package main |
切割
字符串在内存形式上比较接近于切片,它也可以像切片一样进行切割来获取子串。子串和母串共享底层字节数组。
1 | package main |
字节切片和字符串的相互转换
在使用 Go 语言进行网络编程时,经常需要将来自网络的字节流转换成内存字符串,同时也需要将内存字符串转换成网络字节流。Go 语言直接内置了字节切片和字符串的相互转换语法。
1 | package main |
从节省内存的角度出发,你可能会认为字节切片和字符串的底层字节数组是共享的。但是事实不是这样的,底层字节数组会被拷贝。如果内容很大,那么转换操作是需要一定成本的。
那为什么需要拷贝呢?因为字节切片的底层数组内容是可以修改的,而字符串的底层字节数组是只读的,如果共享了,就会导致字符串的只读属性不再成立。
字符串拼接
直接使用运算符
1 | func BenchmarkAddStringWithOperator(b *testing.B) { |
golang 里面的字符串都是不可变的,每次运算都会产生一个新的字符串,所以会产生很多临时的无用的字符串,不仅没有用,还会给 gc 带来额外的负担,所以性能比较差
fmt.Sprintf()
1 | func BenchmarkAddStringWithSprintf(b *testing.B) { |
内部使用 []byte 实现,不像直接运算符这种会产生很多临时的字符串,但是内部的逻辑比较复杂,有很多额外的判断,还用到了 interface,所以性能也不是很好
strings.Join()
1 | func BenchmarkAddStringWithJoin(b *testing.B) { |
join会先根据字符串数组的内容,计算出一个拼接之后的长度,然后申请对应大小的内存,一个一个字符串填入,在已有一个数组的情况下,这种效率会很高,但是本来没有,去构造这个数据的代价也不小
buffer.WriteString()
1 | func BenchmarkAddStringWithBuffer(b *testing.B) { |
这个比较理想,可以当成可变字符使用,对内存的增长也有优化,如果能预估字符串的长度,还可以用 buffer.Grow() 接口来设置 capacity
大量字符串拼接性能测试
1 | / fmt.Printf |
1 | ~/gopath/src/test/string go test -bench="." |
单次字符串拼接性能测试
1 | func BenchmarkFmtSprintf(b *testing.B) { |
1 | ~/gopath/src/test/string go test -bench="." |
结论
- 在已有字符串数组的场合,使用
strings.Join()能有比较好的性能 - 在一些性能要求较高的场合,尽量使用
buffer.WriteString()以获得更好的性能 - 性能要求不太高的场合,直接使用运算符,代码更简短清晰,能获得比较好的可读性
- 如果需要拼接的不仅仅是字符串,还有数字之类的其他需求的话,可以考虑
fmt.Sprintf()
1 | package main |