摘要
本文学习过程中记录
学习心得
经过几天路飞学院爬虫课程的学习,了解了爬虫的本质以及相关的基本知识,今天开始学习爬虫框架scrapy。
前两天的课程学习中应用的是requests和bs4模块,scrapy框架与这两个模块相比无论是速度还是在便捷性上提高的不是一点半点,但是前两天的学习并不是无用的。
前两天的学习了解到整个爬虫的思想以及流程,还有理解如何提高爬虫效率的方法,能够在学习scrapy框架的过程中更深入理解,有一种恍然大悟的感觉,整个学习过程是循序渐进的,感谢路飞学院的这次课程。
scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
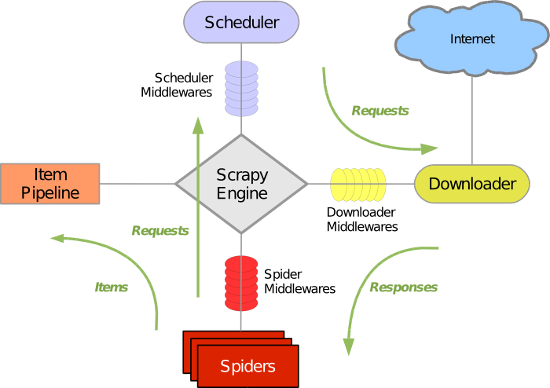
Scrapy主要组件
引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
- 先执行start_requests,返回的结果会转换成迭代器
- 解析器
- 将字符串转换成对象 xpath
- 不加 标签对象
- extract 列表
- extract_first 第一个值
- pipelines
- 多个 数值小优先级高
- 多个,返回值会传递给下一个pipelines的process_item
- from scrapy.exceptions import DrapItem 丢弃 raise DrapItem()
- 先判断是否有from_crawler
- 有 obj = FilePipline.from_crawler()
- 没有 obj = FilePipline()
- 根据配置文件读取相关值,再进行pipeline处理
- POST/请求头/cookie
- 去重
- url存数据库用hash
- url不应该放数据库,应该放redis中(集合)
- request_fingerprint 可以生产url唯一标识
- dont_filter 默认False 去重
安装
1 | Linux |
基本使用
基本命令
1 | scrapy startproject 项目名称 |
项目结构以及爬虫应用简介
1 | project_name/ |
文件说明:
- scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
1 | import scrapy |
运行
1 | import scrapy |
进入project_name目录,运行命令
1 | scrapy crawl spider_name --nolog |
对于上述代码重要之处在于:
- Request是一个封装用户请求的类,在回调函数中yield该对象表示继续访问
- HtmlXpathSelector用于结构化HTML代码并提供选择器功能
选择器
1 | #!/usr/bin/env python |
注意:settings.py中设置DEPTH_LIMIT = 1来指定“递归”的层数。
更多选择器规则:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/selectors.html
格式化处理
上述实例只是简单的图片处理,所以在parse方法中直接处理。如果对于想要获取更多的数据,则可以利用Scrapy的items将数据格式化,然后统一交由pipelines来处理。
在items.py中创建类:
1 | # -*- coding: utf-8 -*- |
上述定义模板,以后对于从请求的源码中获取的数据同意按照此结构来获取,所以在spider中需要有一下操作:
spider
1 | from ..items import IsmeItem |
此处代码的关键在于:
- 将获取的数据封装在了Item对象中
- yield Item对象 (一旦parse中执行yield Item对象,则自动将该对象交个pipelines的类来处理)
pipelines
1 | from scrapy.exceptions import DropItem |
在settings.py中做如下配置:
1 | ITEM_PIPELINES = { |
递归的访问
以上的爬虫仅仅是爬去初始页,而我们爬虫是需要源源不断的执行下去,直到所有的网页被执行完毕
1 | # -*- coding: utf-8 -*- |
以上代码将符合规则的页面中的图片保存在指定目录,并且在HTML源码中找到所有的其他 a 标签的href属性,从而“递归”的执行下去,直到所有的页面都被访问过为止。以上代码之所以可以进行“递归”的访问相关URL,关键在于parse方法使用了 yield Request对象。
注:可以修改settings.py 中的配置文件,以此来指定“递归”的层数,如: DEPTH_LIMIT = 1
cookie
获取原始cookie以及解析后的cookie
1 | # 原始cookie |
登录抽屉并点赞
手动操作cookie
1 | import scrapy |
自动处理cookies
1 | # -*- coding: utf-8 -*- |
中间件
爬虫中间件
1 | class SpiderMiddleware(object): |
下载中间件
- 可以在请求前和请求之后定制一些功能
- 所有请求头操作一些自定义的东西,如加个user-agent
- 自动处理的cookies本质上也是使用的下载中间件
1 | class DownMiddleware1(object): |
代理
代理,需要在环境变量中设置
方式一:使用默认,内置添加代理功能
1 | # 可以在start_requests里面加上 |
方式二:使用自定义下载中间件
1 | from scrapy.contrib.downloadermiddleware.httpproxy import HttpProxyMiddleware |
避免重复访问
scrapy默认使用 scrapy.dupefilter.RFPDupeFilter 进行去重,相关配置有:
1 | DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter' |
自定义URL去重操作
1 | from scrapy.dupefilter import BaseDupeFilter |
自定义命令
- 在spiders同级创建任意目录,如:commands
- 在其中创建 crawlall.py 文件 (此处文件名就是自定义的命令)
1 | from scrapy.commands import ScrapyCommand |
- 在settings.py 中添加配置 COMMANDS_MODULE = ‘项目名称.目录名称’
- 在项目目录执行命令:scrapy crawlall
单个爬虫
1 | import sys |
自定义扩展
自定义扩展时,利用信号在指定位置注册指定操作
1 | from scrapy import signals |
其他
1 | # -*- coding: utf-8 -*- |
更多请参见Scrapy文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html